Introduction:
LibDocAnax is a high-performance, C++ document intelligence engine designed to serve as the "Ground Truth" layer for Enterprise AI. By moving beyond simple text extraction, LibDocAnax establishes a Digital Evidence Chain that binds raw document sources to downstream AI decisions through cryptographic lineage and deterministic structure.
- Positioning: From Data Pipeline to Structural Contract
LibDocAnax provides the Deterministic Extraction Layer required for regulated industries (LegalTech, Insurance, FinTech). It bridges the gap between messy unstructured documents and LLM-driven automation by providing a "structural contract"—a JSON-based map that ensures every piece of data is traceable, hashed, and verified.
- Core Enhancements
Our latest release introduces critical capabilities for "Evidence-Based AI":
- Hybrid Extraction: Unified support for both Structural (Digital) and Scanned documents.
- Governance-Ready JSON: Introduction of the v0.1 Governance Spec, featuring:
- Stable Hashing: Content-position binding via SHA-256 for audit trails.
- Canonicalization Policies: Removing formatting noise while preserving legal integrity.
- Source-to-Output Traceability: Precise bounding box coordinates and page-paragraph lineage.
- Advanced Linguistics: First-class Chinese Word Segmentation and CJK support, enabling precise analysis of complex scripts.
- Deterministic vs. Generative Extraction
Unlike AI-based extractors that may "hallucinate" document structure, LibDocAnax utilizes Deterministic Structural Extraction.
- Rules-Based Parsing: Uses layout-aware heuristics to identify headers, tables, and segments.
- Lightweight Understanding: Efficient, C++ native logic provides "document IQ" without the heavy compute or privacy risks of cloud-based models.
- Tabular Fidelity: Reconstructs complex data into explicit structures (e.g., Markdown) to ensure LLMs maintain column-row alignment.
- The AI Evidence Chain Workflow
LibDocAnax is the "Anchor" in the governance loop:
- Ingest: Natively parse PDF, Word, Excel, and Images.
- Structure: Generate a JSON Evidence Map with unique Segment IDs.
- Hash: Bind every paragraph to its document source with a SHA-256 fingerprint.
- Audit: Enable downstream LLMs to cite specific, hashed segments for "Signed Decision Artifacts."
- Roadmap: The Path to Enterprise Maturity
We are actively expanding LibDocAnax to include:
- Complex Table Refinement: Handling irregular grids and nested cells.
- Deep Traceability: Word-level page position tracking and auto-correction for "dirty" OCR.
- Performance at Scale: Parallel image extraction and mmap-driven fast file access for massive document sets.
- Advanced Analytics: Document duplication checking and word occurrence ranking.
- Security and Deployment
LibDocAnax remains fully offline and on-premises. It is designed for environments where data privacy is non-negotiable. By exposing only structured, hashed data to AI models, enterprises can maintain a "Zero-Trust" posture regarding their most sensitive intellectual property.
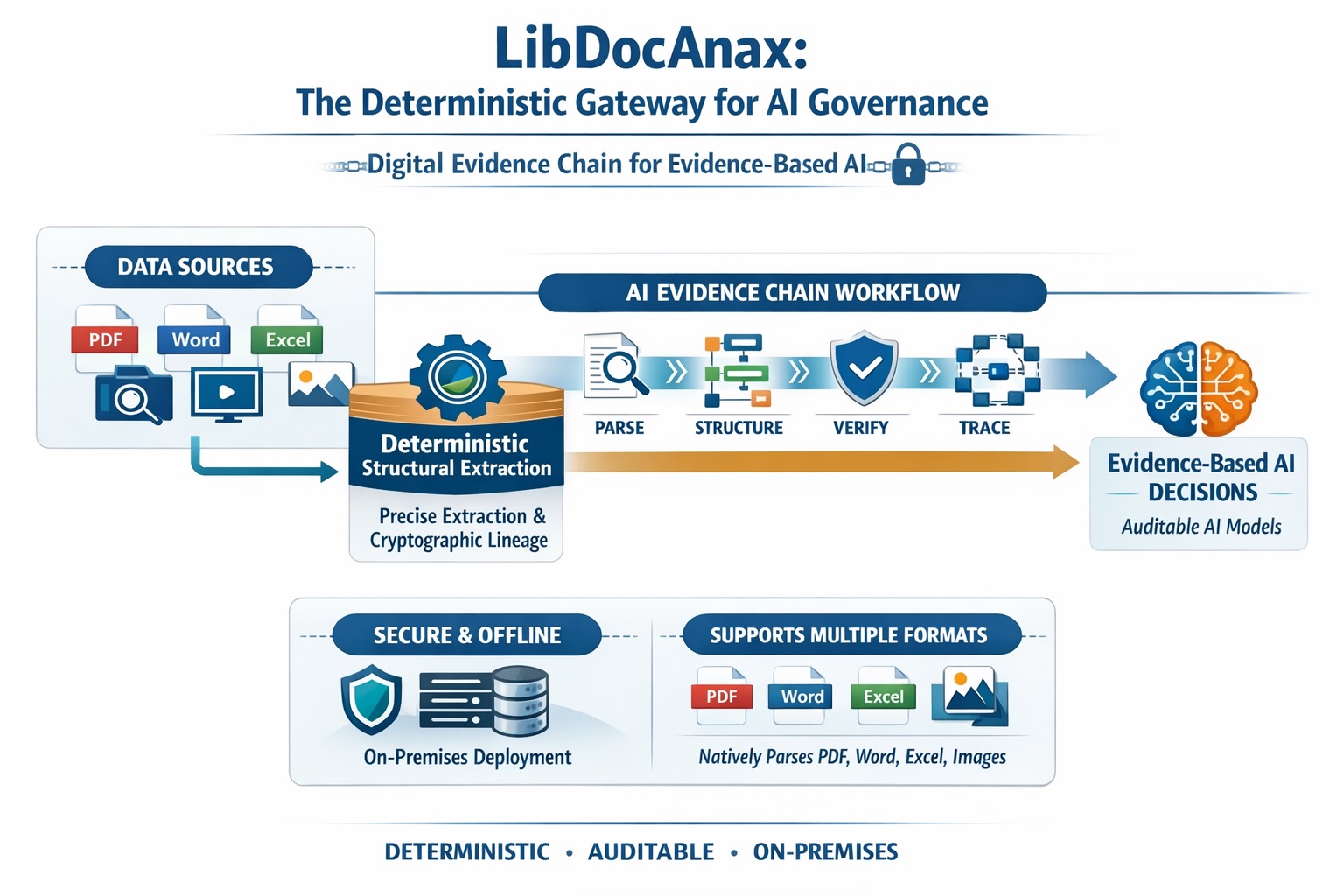
Illustration diagram designed by Gemini Banana Pro2